

阿聯酋阿布扎比技術創新研究所(Technology Innovation Institute,簡稱TII)在官網發布了,目前性能最強的開源大語言模型之一Falcon 180B。
TII表示,Falcon 180B擁有1800億參數,使用4096個GPU在3.5萬億token 數據集上進行訓練,這也是目前開源模型里規模最大的預訓練數據集之一。Falcon 180B有基礎和聊天兩個模型,允許商業化。
Falcon 180B在多個權威測試平臺中,在推理、編程、知識測試等方面,超過了Meta最新發布的 Llama 2 70B 和 OpenAI 的 GPT-3.5,可媲美谷歌的PaLM 2-Large僅次于GPT-4。
基礎開源地址:https://huggingface.co/tiiuae/falcon-180B
聊天開源地址:https://huggingface.co/tiiuae/falcon-180B-chat
在線測試地址:https://huggingface.co/spaces/tiiuae/falcon-180b-demo
今年5月,「AIGC開放社區」曾介紹過TII發布的一款類ChatGPT開源大語言模型Falcon-40B。
該產品剛推出便成為Huggingface的開源大語言模型排行第一名,擊敗了LLaMa 65b、GPT4-X-Alpasta-30b、LLaMa 30b等眾多著名開源項目成為一匹黑馬。
Falcon 180B便是在Falcon-40B基礎之上研發而成,并將模型參數擴大了4.5倍,訓練集從1萬億提升至3.5萬億token,并在算法、推理、硬件部署方面進行了大幅度優化。
其中,最大的亮點就是Falcon 180B- chat版本支持中文,并進行了數據微調。
Falcon 180B簡單介紹
預訓練方面,Falcon 180通過使用 Amazon SageMaker 在多達4096個GPU上同時對3.5萬億個token數據集進行訓練,總共花費了約 7,000,000個小時。
TII表示,Falcon 180B的規模是Llama 2的2.5 倍,而訓練所需的算力資源是Llama 2的4倍。
Falcon 180B的訓練數據集主要來自RefinedWeb的網絡數據(大約占85%)。還在對話、技術論文和一小部分代碼 (約占 3%) 等,經過整理的混合數據的基礎上進行了訓練。
Falcon 180B-chat模型在聊天和指令數據集上進行了微調,并混合了多個大規模對話數據集,使其能夠更好地理解用戶的文本提示意圖,生成絲滑、流暢、擬人化的各種文本內容。
Falcon 180B性能評測
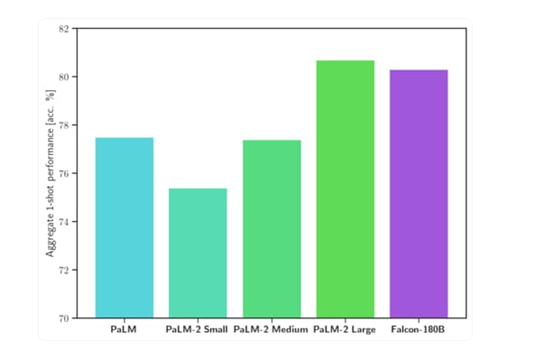
Falcon 180B在MMLU上的測試結果,優于Llama 2 70B 和 OpenAI 的 GPT-3.5;在 HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC等測試中,可媲美谷歌的PaLM 2-Large。
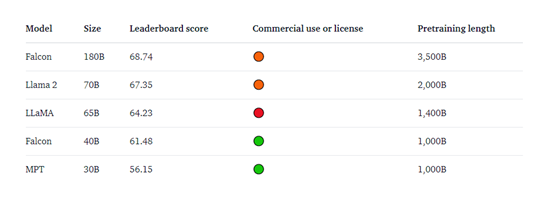
目前,Falcon 180B在Hugging Face排行榜上得分為68.74,是得分最高的公開發布的預訓練大語言模型,超越了Meta的 LLaMA 2、LLaMA等。
Falcon 180B- chat使用體驗
「AIGC開放社區」通過在線demo體驗了一下Falcon 180B- chat,使用方法和ChatGPT一樣,中文生成的內容基本達到了GPT-3.5的效果,支持單話題,多輪深度詢問。
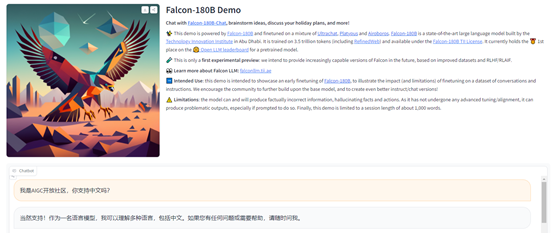
例如,詢問,中國歷史上有哪些著名詩人?Falcon 180B- chat可以按照羅列的方式,列出最知名的詩人。
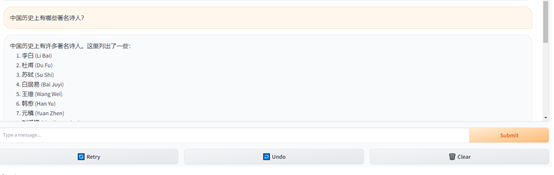
讓其詳細介紹一下李白。

再介紹一下李白對現代人的影響。Falcon 180B- chat的整體回復內容非常絲滑、流暢。

關于TII
TII 成立于2020年,是阿布扎比高等教育和科技部 (ADEK) 旗下的研究機構。TII 的目標是推動科學研究、開發前沿技術并將其商業化,以促進阿布扎比和阿聯酋的經濟發展。
目前,TII擁有來自 74個國家的800多名研究專家,發表了 700 多篇論文和 25 多項專利,是世界領先的科學研究機構之一。
本文素材來源TII,如有侵權請聯系刪除
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > 1800億參數,支持中文,3.5萬億訓練數據!開源類ChatGPT模型
heng.png)
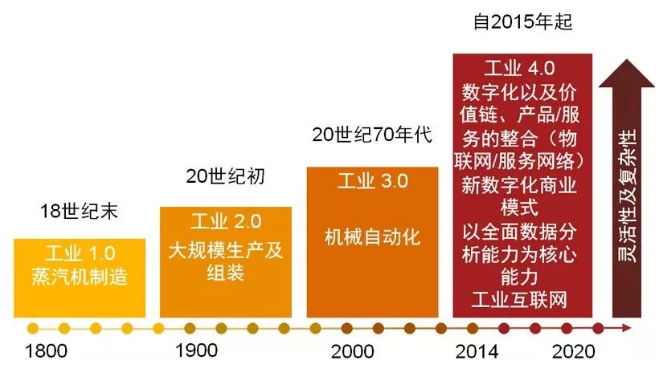
 為何說數字化的本質就是自動化
為何說數字化的本質就是自動化 科技爆炸,白領辦公新style,工作吩咐一聲,電腦自動完成
科技爆炸,白領辦公新style,工作吩咐一聲,電腦自動完成 如何通過人工智能和自動化提高供應鏈彈性?
如何通過人工智能和自動化提高供應鏈彈性? 經濟蕭條下,RPA投入應該被“犧牲”掉嗎?
經濟蕭條下,RPA投入應該被“犧牲”掉嗎?









熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國