

導讀
如何把你的人工智能想法轉化為可用的軟件。

建立一個 AI PoC 是困難的。在這篇文章中,我將解釋我的思維過程,使我的人工智能 PoCs 成功。
“我的鬧鐘能不能利用交通信息及時叫醒我去上班?”我們都想過求助于人工智能來解決我們的一個問題。概念證明(PoC)的目標是測試是否值得在其中投入時間。構建 PoC 是困難的,但構建 AI PoC 則更加困難,因為它需要大量的技能。
在構建 AI PoC 時,數據科學只是工作的一小部分,但它是最重要的技能之一。很容易找到一些非常好的教程來教你如何解決一個特定的任務,如何構建一個檢測算法來停車入庫。如何部署一個 flask app 到云上。但是,為你的特定問題設計一個解決方案要困難得多,這主要是因為你需要后知后覺地將問題重新組織成標準化的任務。
在這篇文章中,我將解釋我實現這一目標的方法。
首先,我將回顧一下人工智能系統是什么樣子的。然后,我將描述我設計一個人工智能的 3 個步驟的過程。最后,我們將看到兩個示例,一個簡單的示例和一個完整的帶有 python 實現的示例。
人工智能系統概述
作為一個例子,我將使用一個分類文件的系統來說。它回答的問題是,“這是什么類型的文件?答案是類似于“電子發票”或“待辦事項”這樣的類。
AI 工作流程包含 5 個步驟:
-
收到問題: “這是什么類型的文件? ” -
在用戶或上下文中添加補充數據: “用戶擁有什么類型的文件? ” -
使用數據回答問題: “這個文件屬于哪種類型? ”,"這是能源發票" -
存儲結果: 添加新文件到數據庫 -
回答客戶的問題: “這是能源發票”
你可以把它分成 3 個任務或語義塊:
-
處理客戶:接受問題,讓他等待……
示例:HTTP 服務器
-
數據調取:與“公司知識庫”溝通,增加或接收相關數據。
與數據庫的通信
-
AI 部分:回答這個問題的 AI 本身,以及上下文。
例子:專家系統,支持向量機,神經網絡…

你可以在網上找到關于如何架設你的服務器或數據調取層的教程。Python 中最簡單的 AI PoC 解決方案是使用 Flask 和 SQL 數據庫,但這在很大程度上取決于你的需要和你已經擁有的東西。我們將專注于設計 AI 本身。
設計 AI 部分
人工智能任務可能涉及多個異構輸入。例如,用戶的年齡和位置或整個電子郵件討論。
人工智能的輸出取決于任務:我們想要回答的問題。人工智能有很多不同的任務。在下面的圖片中,你可以看到一些常見的計算機視覺任務。

一旦你從標準化的輸入和任務中走出來,想辦法構建一個人工智能就會變得很復雜。
為了讓我了解構建 AI 的復雜性,我使用了一個 3 步的過程。
步驟 1:瀏覽相關的輸入
首先,收集你覺得能夠回答手頭任務的所有輸入,并選擇在大多數情況下能夠自給自足的輸入。
在測試人工智能想法時,很容易變得貪婪,并考慮包含大量輸入的解決方案:例如,用戶的位置可能會讓我了解他們的下一封電子郵件是什么。事實是:人們很容易迷失在各種不同含義或性質的輸入中,最終什么也得不到。
在建造你的 AI 時,堅持簡單的,自給自足的輸入。
步驟 2: 數據向量化
第二步是對這些輸入進行預處理,使其可用于各種算法。在某種程度上,每一個 AI 過程都要經過一系列的步驟來獲得一個向量表示。
這個過程非常簡單,比如計算單詞在文檔中出現的頻率,或者直接使用圖像像素的值。它也可以變得非常復雜的多層預處理。

輸入可以是非常不同的:不同的大小、顏色比例或圖像格式。請記住,這里的思想是構建所有輸入的有意義的、規范化的表示。
構建規范化的輸入和有意義的表示。
步驟 3:處理向量
第三步是考慮輸出和如何實現輸出的時刻。
與輸入一樣,輸出也需要“向量化”。對于分類,它很簡單:按類劃分一個字段。
然后,我們需要找到從輸入向量到輸出向量的方法。最后,這是我們開始尋找 AI 時學到的第一件事。它可以涉及到一些簡單的任務,比如找到最近的向量或最大值,也可以涉及到更復雜的任務,比如使用巨大的神經網絡架構。
大多數任務,如回歸、分類或推薦,都有詳細的文檔記錄。對于 PoC,最簡單的操作是使用一個預先實現的算法庫,如scikit-learn[1]并進行測試。

找一些簡單的和預先實現好的算法。
一個直接的例子
任務:文本是法語還是英語?
解決方案:
步驟 1:瀏覽相關輸入。如果沒有任何源或其他元數據,文本是惟一可能的輸入。
步驟 2:向量化數據。向量化的一個簡單方法是計算英語單詞和法語單詞的數量。我們將使用特定語言中最常用的單詞。它們被稱為停用詞:the, he, him, his, himself, she, her…
步驟 3:處理向量。然后,我們可以選擇使用這兩個值中最高的值進行分類,以獲得二進制輸出:True 或 False。
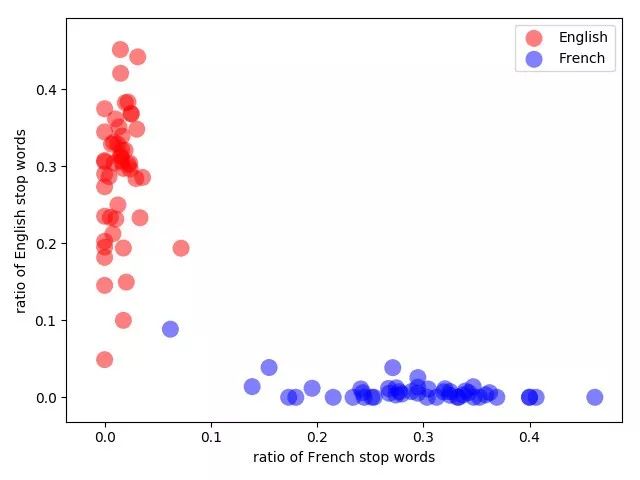
維基百科中法語和英語的頁面按照詞綴比例隨機劃分。藍色的異常值是關于 Ferroplasmaceae 的法語頁面,遺憾的是,它包含的英語參考文獻比法語句子還多。
構建人工智能通常是人類專長(商業知識)和計算機智能(機器學習)的混合。在這個例子中,由于法語和英語的停用詞,我使用了人類的專業知識來選擇如何構建我的向量。我也可以使用機器學習來訓練一個模型,要么構建一個相應的向量(步驟 2),要么學習更復雜的向量的分類(步驟 3)。
一個更復雜一點的問題
在一次會議上,我與一個從事數字安全項目的人交談。他告訴我,他想幫助他的用戶對他們的個人文檔進行分類和排序:合同、賬單、文件……他注意到,隨著存儲的內容越來越多,文件夾樹也越來越復雜,人們往往會對自己的文檔進行錯誤的分類。找到他們想要的內容也變得更加困難。搜索引擎只是在“修補”問題,而不是消除根本原因:只有在知道準確信息的情況下才能找到文檔,而文件夾仍然很混亂。
那么我們該如何解決這個問題呢?
注:我真的開發了這樣一個系統:https://github.com/Wirg/digital-safe-document-classification
闡明 PoC 的思想并定義其范圍
我們將設計一個用戶界面,用戶可以上傳一個文檔,然后提示用戶這個文檔最適合的文件夾是什么。我們希望支持這些類型的文件:txt、text、markdown 和 pdf。
“data_to_read”是我放想要閱讀的文章的文件夾。Work 是一個文件夾,里面有我以前的學校報告(主要是數據科學項目)。在 15 個文件夾中選擇 2 個。具體實現:https://github.com/Wirg/digital-safe-document-classification。
我們想要提示用戶的是他們當前的文件夾,而不是舊的或來自其他人的文件夾:答案必須是特定于用戶和特定于時間的。
步驟 1:瀏覽相關的輸入
首先,我們需要知道用戶的文件夾,否則我們將無法回答。要做出選擇,我們可以使用:
-
文件的內容 -
添加時間: 有些賬單可能是按月支付的,有些任務可能大部分是在特定時間內完成的 -
文件名和類型: " energy_invoice_joe_march.pdf "、“pdf”
在我們的例子中,最可靠的輸入可能是文檔的內容。我們將使用上傳的文檔和用戶文件夾的內容作為比較。我們來關注一下。
步驟2: 輸入向量化
現在,我們有不同的輸入格式:pdf、markdown、text、txt…我們可以直接處理 markdown 和其他文本格式的文件內容。但是我們必須處理 pdf 文件,才能像其他文件一樣使用它們。
我通過谷歌搜索找到了這里使用的工具 Pdftotext。它是有效的,但有一個巨大的缺點,它不執行光學字符識別(OCR)。這意味著它將讀取大多數 pdf 文件,但無法讀取由圖像或掃描件創建的文件。為了解決這個問題,我可以使用像 Tesseract 這樣的替代方法,但是我不會在這個例子中使用。
我們想把文本轉換成向量,讓我們來看看scikit-learn[2]。我們找一個文本向量化的工具,我們找到一個文本的特征提取包。這正是我們要找的。它有兩個向量化工具:一個基于單詞計數,另一個稱為 TfidfVectorizer,我們使用的就是這個。

Tfidf 表示詞頻和逆文檔頻率。它基本上是數字,但用了一種更聰明的方法。其思想是,我們不只是計算單詞的數量,而是通過計算單詞的頻率,并將其與文檔中的單詞數量進行比較,從而了解文檔中某個單詞的重要性:詞頻(term frequency, TF)。然后,我們將其頻率與文檔數量進行比較。文檔中出現的頻率越少,它對文檔的影響就越大:逆文檔頻率(IDF)
步驟 3:處理向量
我們需要一個最佳文件夾的列表作為最終輸出。將文件夾名映射到數字很簡單。但是我們不能得到一個簡單的標準化輸出向量因為輸出向量的大小會改變。實際上,文件夾的數量在很大程度上取決于用戶及其當前文件夾。由于這個原因,我們不能使用固定數量的類的普通分類算法。我們需要每次都對模型進行重新訓練,并為每個用戶構建一個模型,或者為所有用戶構建一個大型模型。
但是我們已經在向量化過程中加入了“智能”。因此,我們將采取另一種方法,更類似于搜索引擎:對上傳的文檔、文件夾中已經存在的文檔進行矢量化,并比較結果向量。
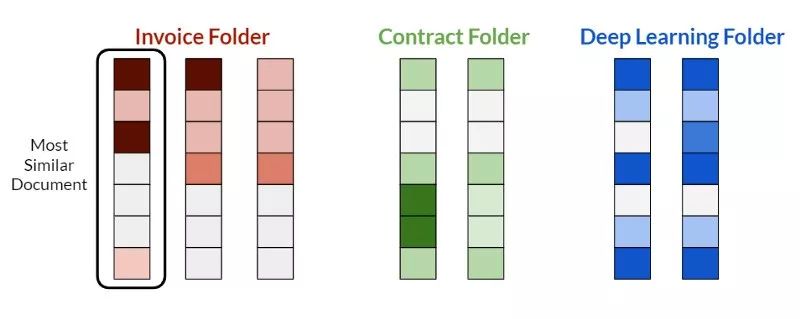
為了找到最好的文件夾,我們尋找與上傳文檔最匹配的文檔。
我們找到向量表示與上傳文檔最相似的文檔,并將通過它找到原始文件夾。
使用余弦相似性查找最佳文件夾。
總而言之,解決 AI 問題可以簡化為以下 3 個步驟:
-
首先,瀏覽相關輸入 -
其次,向量化數據 -
第三,處理向量
我希望它能幫助你實現你的人工智能想法。
英文原文:https://www.sicara.ai/blog/2019-03-29-how-build-succesful-ai-poc
特別聲明:
文章來源:AI公園(AI_Paradise)
作者:Arnault
編譯:ronghuaiyang
原文鏈接:https://mp.weixin.qq.com/s/pAUOCvUPEHf-EwTGuG04YA
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > 如何構建一個成功的AI PoC(Prove of Concept)
heng.png)
 達觀助手智能寫作產品正式發布,全面提升寫作能力!
達觀助手智能寫作產品正式發布,全面提升寫作能力! 生成式AI為何不完全適用當下B2B行業?
生成式AI為何不完全適用當下B2B行業? Gartner:ChatGPT只是開始,企業生成式AI的未來
Gartner:ChatGPT只是開始,企業生成式AI的未來 ?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望
?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望











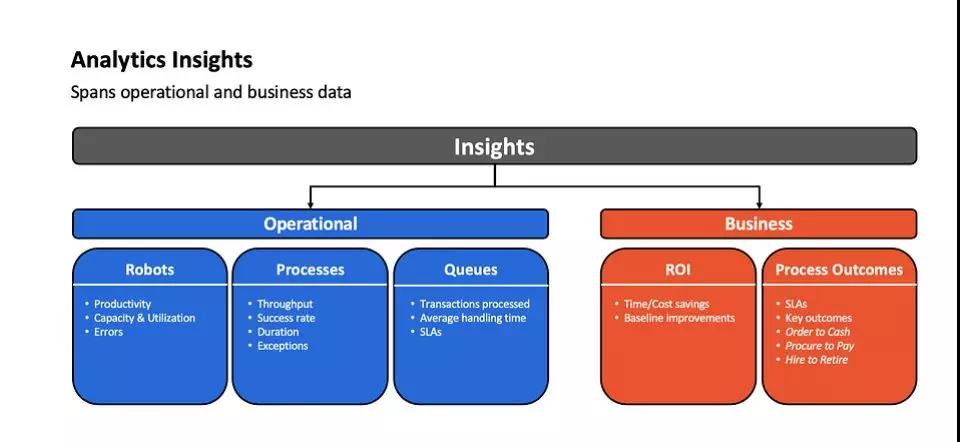

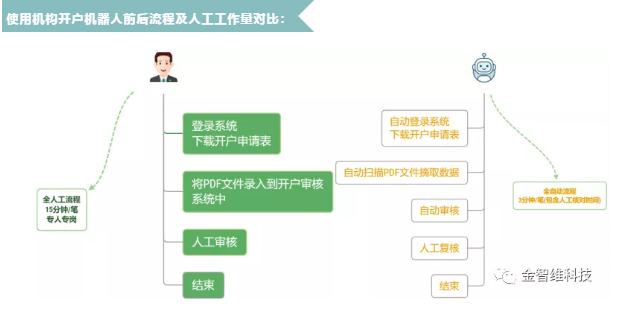

熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國