隨著擴散模型的飛速發展,誕生了Midjourney、DALL·E 3、Stable Difusion等一大批出色的文生圖模型。但在文生視頻領域卻進步緩慢,因為文生視頻多數采用逐幀生成的方式,這類自回歸方法運算效率低下、成本高。
即便使用先生成關鍵幀,再生成中間幀新方法。如何插值幀數,保證生成視頻的連貫性也有很多技術難點。
科技、社交巨頭Meta則提出了一種全新的文生視頻模型Emu Video。該模型使用了分解式生成方法,先生成一張圖像,再以該圖像和文本作為條件生成視頻,不僅生成的視頻逼真符合文本描述,算力成本也非常低。
論文:https://emu-video.metademolab.com/assets/emu_video.pdf
在線demo:https://emu-video.metademolab.com/#/demo
Emu Video的核心技術創新在于,使用了分解式生成方法。之前,其他文生視頻模型是直接從文本描述映射到高維視頻空間。
但由于視頻維度非常高,直接映射非常困難。Emu Video的策略是首先生成一張圖像,然后以該圖像和文本作為條件,生成隨后的視頻幀。
由于圖像空間維度較低,生成第一幀更容易,然后生成后續幀只需要預測圖像如何變化,這樣整個任務難度很大程度降低。
技術流程方面, Emu Video利用先前訓練好的文本到圖像模型來固定空間參數,初始化視頻模型。
然后僅需要訓練時間參數來進行文本到視頻任務。在訓練時,模型以視頻片段及相應文本描述作為樣本進行學習。
在推理時,給定一段文本后,先用文本到圖像部分生成第一幀圖像,再輸入該圖像及文本到視頻部分生成完整的視頻。
Emu Video使用了一個訓練好的文本到圖像模型,可以生成很逼真的圖片。為了讓生成的圖片更有創意,這個模型在海量的圖像和文本描述進行預訓練,學到了很多圖像的風格,例如,朋克、素描、油畫、彩繪等。
文本到圖像模型采用了U-Net結構,包含編碼器和解碼器。編碼器包含多層卷積塊,并降采樣獲得較低分辨率的特征圖。
解碼器包含對稱的上采樣和卷積層,最終輸出圖像。兩個文本編碼器(T5和CLIP模型)被并行加入,分別對文本進行編碼產生文本特征。
這個模塊使用了跟文本到圖像模塊類似的結構,也是一個編碼器-解碼器結構。不同的是增加了處理時間信息的模塊,也就是說可以學習如何把圖片中的內容變化成一個視頻。
在訓練的過程中,研究人員輸入一小段視頻,隨機抽取其中的一幀圖片,讓這個模塊學習根據這張圖片和對應的文本生成整段視頻。
在實際使用時,先用第一個模塊生成第一幀圖片,然后輸入這張圖片和文本給第二個模塊,讓它生成整個視頻。
這種分解的方法讓第二個模塊的任務變得比較簡單,只需要預測圖片會隨著時間而怎么變化和運動,就可以生成流暢逼真的視頻。
為了生成更高質量逼真的視頻,研究人員進行了一些技術優化:1)采用零終端信噪比的散度噪聲計劃,能夠直接生成高清視頻,無需級聯多個模型。之前的計劃在訓練和測試階段信噪比存在偏差,導致生成質量下降。
2)利用預訓練文本到圖像模型固定參數,保留圖像質量和多樣性,生成第一幀時不需額外訓練數據和計算成本。
3)設計多階段訓練策略,先在低分辨率訓練快速采樣視頻信息,再在高分辨率進行微調,避免全程高分辨率的計算量大。
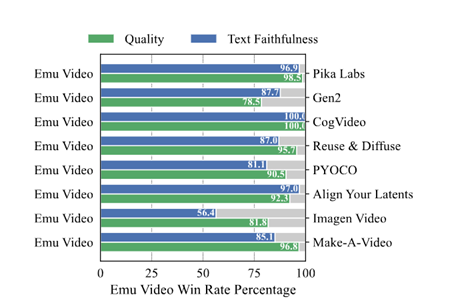
在人類評估中顯示,Emu Video生成的4秒長視頻比其他方法更具質量和遵循文本的要求。語義一致性超過86%,質量一致性超過91%,明顯優于Gen-2、Pika Labs、Make-A Video等知名商業模型。
本文素材來源Meta官網,如有侵權請聯系刪除
繼續閱讀:
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > 對標Gen-2!Meta發布新模型,進軍文生視頻賽道






heng.png)
 達觀助手智能寫作產品正式發布,全面提升寫作能力!
達觀助手智能寫作產品正式發布,全面提升寫作能力! 生成式AI為何不完全適用當下B2B行業?
生成式AI為何不完全適用當下B2B行業? Gartner:ChatGPT只是開始,企業生成式AI的未來
Gartner:ChatGPT只是開始,企業生成式AI的未來 ?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望
?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望














熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國