

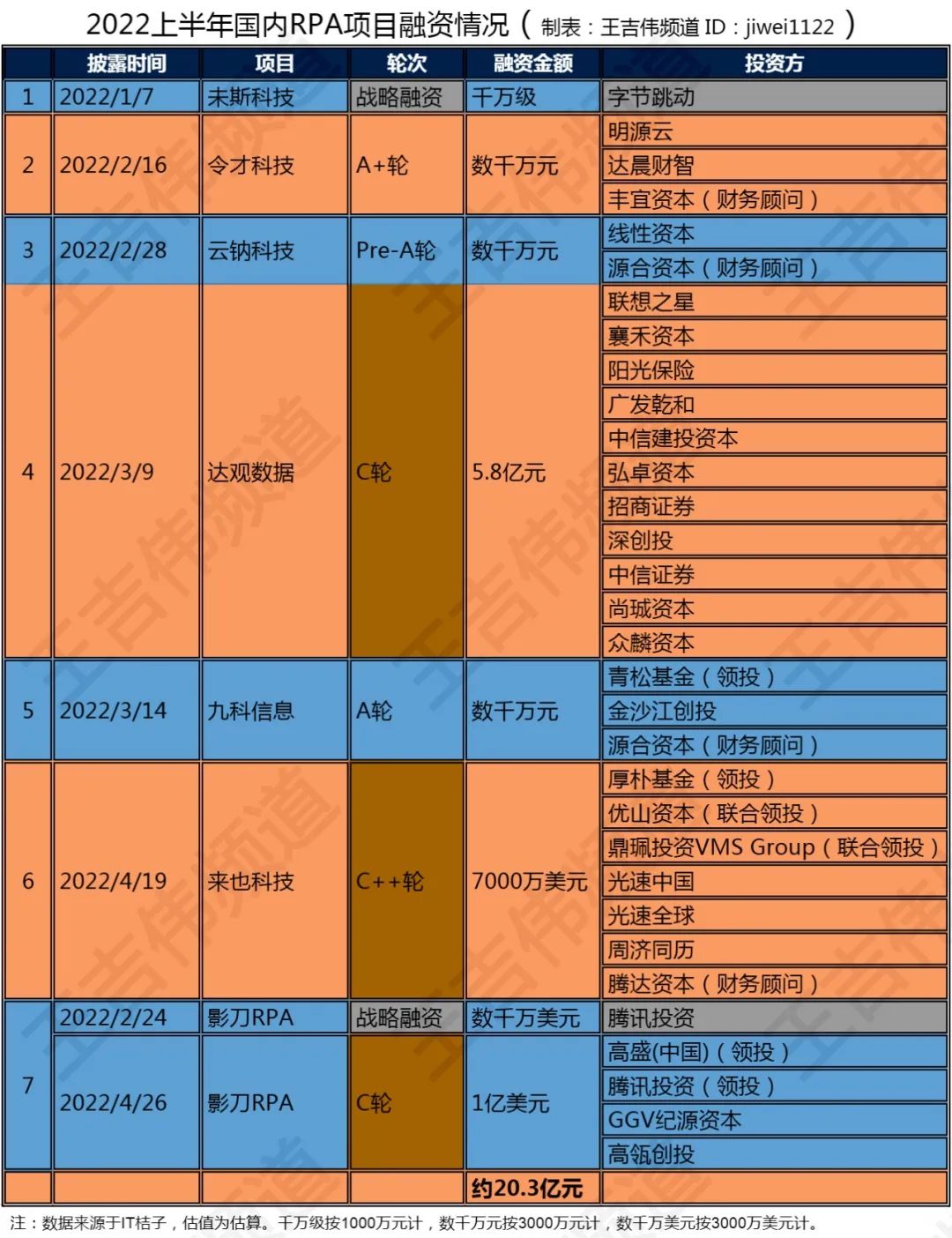
字節跳動的研究人員開發了一種超高清文生視頻模型MagicVideo-V2。
MagicVideo-V2公布的實驗評測數據顯示,視頻的高清度、潤滑度、連貫性、文本語義還原等方面,比目前主流的文生視頻模型Gen-2、Stable Video Diffusion、Pika 1.0等更出色。
這是因為,MagicVideo-V2將文生圖像、圖像生成視頻、視頻到視頻和視頻幀插值4種功能整合到一個模型中,解決了之前面臨的4大難題。
論文地址:https://arxiv.org/abs/2401.04468
項目地址:https://magicvideov2.github.io/

一只穿著紫色長袍的胖兔子,走過一片魔幻的風景(由MagicVideo-V

隨著Gen-2等模型的出現,文生視頻領域實現飛速發展,尤其是在這個短視頻時代被大量用戶應用。但是在生成的過程中,模型經常面臨4個難題。

一個女巫正在制作藥品
視頻不美觀,由于多數是采用公開訓練數據,生成的視頻經常會出現劣質的情況;內容不一致,在生成視頻的過程中,無法精準還原文本提示的內容;
視覺質量和清晰度較差:如何將用戶的文本提示,轉化為高清、精準高質量視頻很難;
視頻運動不連貫,多數模型無法在生成的關鍵幀之間,插入額外的幀,使視頻的運動更加自然和連貫性。

所以,字節跳動的研究人員直接將4個模塊整合在MagicVideo-V2模型中,一一解決了這些難題。
文生圖像
文生圖像模塊(Text-to-Image, T2I)主要用于接收用戶提供的文本描述作為輸入,并生成一個1024×1024像素的圖像作為視頻生成的參考圖像。這有助于增強視頻的內容和美學風格。

T2I模型采用基于擴散的生成模型,通過多個迭代步驟逐漸生成高質量的圖像,同時可以學習到從文本描述到圖像的映射關系,從而生成與文本描述相符的精美圖像。
圖像到視頻
該模塊基于SD1.5模型,通過人類反饋來提高模型在視覺質量和內容一致性方面的能力。圖像到視頻模塊還使用了一個參考圖像嵌入模塊,用于利用參考圖像。
具體來說,研究人員使用了一種外觀編碼器來提取參考圖像的嵌入,并通過交叉注意機制將其注入到圖像到視頻模塊中。

一只熊貓趴在沖浪板上,夕陽,4K超清
這樣,圖像提示可以有效地與文本提示解耦,并提供更強的圖像條件。此外,使用了潛在噪聲先驗策略,通過在起始噪聲潛變量中引入適當的噪聲先驗技巧,保留部分圖像布局,改善幀之間的時間連貫性。
視頻到視頻
該模塊進一步對低分辨率視頻的關鍵幀進行優化和超分辨率處理,以生成高分辨率的視頻。
簡單來說,就像照相機的美顏功能,會根據圖像內容自動生成更豐富的像素級細節,增強整體逼真度與紋理細節。

鋼鐵俠在燃燒的城市人上飛行,細節逼真,4K超高效果
這也是比其他文生視頻模型更高清的重要原因之一。
視頻幀插值
該模塊可以在生成的視頻關鍵幀之間插入額外的幀,增加視頻的平滑性、動態感以及連貫性。
主要通過分析相鄰關鍵幀之間的運動信息,以及參考圖像和文本描述,插入中間幀,使視頻的運動更加連續和自然。
測試數據
為了評估 MagicVideo-V2的性能,研究人員使用了人類評估和目前最先進的 T2V 系統兩種評估方法。
分別由61位評估者組成的小組對 MagicVideo-V2 和另一種 T2V 方法進行了 500 次并排比較。
在每一輪比較中,每位投票者都會看到一對隨機的視頻,包括基于相同文本提示的一個我們的視頻和一個競爭對手的視頻。他們會看到三個評估選項--"好"、"一樣 "或 "壞"--分別表示偏好 MagicVideo-V2、無偏好或偏好競爭的 T2V 方法。

投票者需要根據他們對三個標準的總體偏好進行投票:1) 哪種視頻具有更高的幀質量和整體視覺吸引力。2) 哪種視頻的時間一致性更高,運動范圍和運動連貫性性更好。
3) 哪個視頻的結構錯誤或不良情況更少。測試結果表明,MagicVideo-V2 明顯更受評估者青睞。
本文素材來源MagicVideo-V2論文,如有侵權請聯系刪除
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > 字節跳動推出超高清文生視頻模型,效果比Gen-2更強!
heng.png)
 達觀助手智能寫作產品正式發布,全面提升寫作能力!
達觀助手智能寫作產品正式發布,全面提升寫作能力! 生成式AI為何不完全適用當下B2B行業?
生成式AI為何不完全適用當下B2B行業? Gartner:ChatGPT只是開始,企業生成式AI的未來
Gartner:ChatGPT只是開始,企業生成式AI的未來 ?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望
?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望














熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國