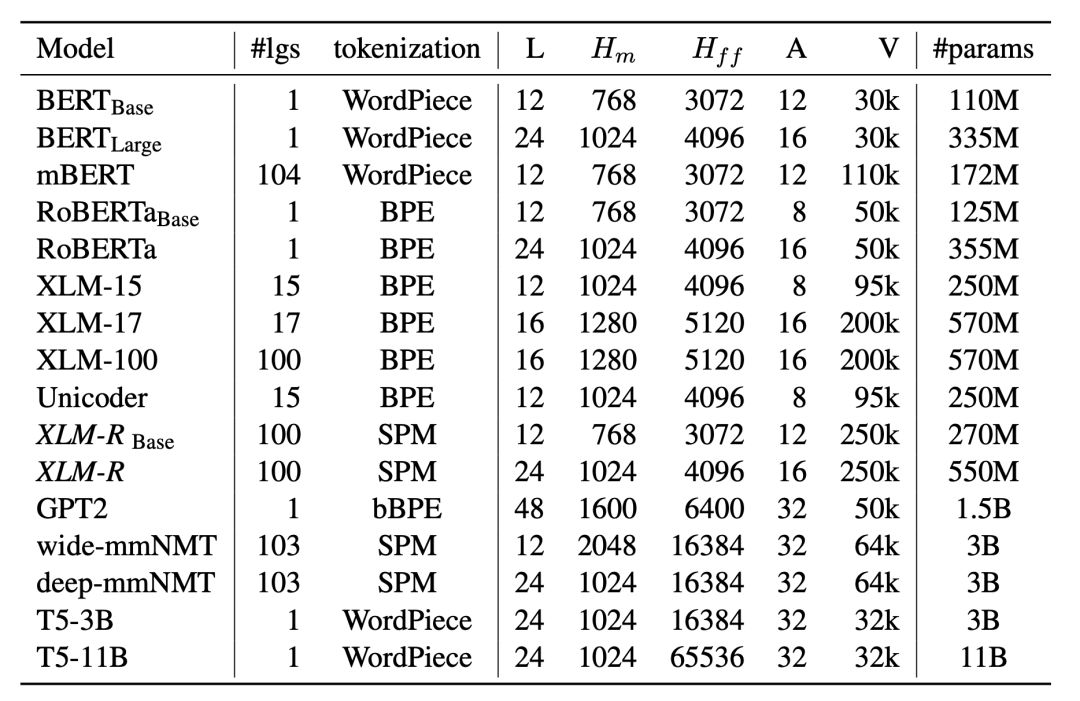
Facebook AI研究部門在自然語言理解方面的最新突破名為XLM-R,可以處理諸多任務,比如針對包括斯瓦希里語和烏爾都語在內的100種不同語言解答問題。 這既表明深度學習模型變得越來越大,還表明它們遇到了現有計算系統中嚴重的資源瓶頸。
Facebook的巨型“XLM-R” 神經網絡經過精心設計,可以 針對 包括斯瓦希里語和烏爾都語在內的100種不同語言 處理 單詞問題,但 即便 使用500個 世界一流的英偉達 GPU,它也遇到了 計算 瓶頸 。
隨著機器學習模型變得越來越大,最先進的AI研究繼續遇到傳統計算技術的瓶頸。
這是Facebook AI團隊的研究人員最新的重大研究工作的成果之一。 上周,他們發布了有關其發明XLM-R的報告; XLM-R是一種自然語言模型,基于谷歌廣受歡迎的Transformer模型。
題為《大規模的無監督跨語言表示學習》的論文( https://arxiv.org/pdf/1911.02116.pdf )發表在arXiv上,論文作者有Alexis Conneau、Kartikay Khandelwal Naman、Goyal Vishrav、Chaudhary Guillaume、Wenzek Francisco Guzmán、Edouard Grave、Myle Ott、Luke Zettlemoyer和Veselin Stoyanov,他們都是Facebook AI研究部門的人員。
XLM-R經過精心設計,能夠在100種不同語言之間進行翻譯。 它基于Conneau今年早些時候與Facebook的Guillaume Lample攜手開展的工作,Facebook創建了最初的XLM。 他們寫道,這與今年早些時候谷歌研究人員展示的對103種語言進行跨語言訓練的那個系統極為相似。
與以前在各種基準測試任務(比如語言之間的問題解答)方面所做的研究工作相比,這是很大的改進。 尤其是,它在所謂的“低資源”語言方面取得了可喜的進步,這些語言沒有太多的文字資料,比如斯瓦希里語和烏爾都語。
但是,盡管使用了500個功能最強大的英偉達GPU,XLM-R仍遇到了資源瓶頸。 論文作者們稱之為“多語言詛咒”。 如果你將越來越多的語言填塞到單單一個端到端的Transformer中,低資源語言將從中受益,但到了一定程度,每種語言都遇到瓶頸。
這是由于XLM-R很大,它有24層、16個“注意力頭”以及5.5億個參數,不過它仍然容量有限。 終究有一天,它可以處理要求它執行的各項任務。
作者們寫道: “模型容量(即模型中參數的數量)由于實際考慮因素而受到限制,比如訓練和推理過程中的內存和速度。 ”
XLM-R被要求處理大量的訓練數據,即使用CommonCrawl程序從網上收集的2.5萬億字節數據。 XLM-R甚至還不是市面上最大的網絡。 OpenAI今年早些時候推出的GPT2其最大版本有48層和15億個參數。 正如Facebook的PyTorch負責人Joe Spisak今年初告訴IT外媒ZDNet,網絡變得越來越大。
就總的參數數量或層數而言,Facebook的“XLM-R”并不是最大的網絡,但它確實因將其許多參數專用于“單詞”(token)而脫穎而出。 Token是指它可以處理的詞匯量,總共是250000個單詞。
但是XLM-R遇到了一些特定的瓶頸,比如可以容納多大的詞匯量。 論文作者構建的該系統以250000個“單詞”作為基準,這已經比GPT-2的50000個單詞要多,但是他們知道: 如果XLM-R擁有的單詞多得多――意味著詞匯量更大,可以變得更好。
論文作者寫道: “有了更龐大的模型,我們認為使用多達200萬個單詞、并使用自適應softmax方法的詞匯量有望進一步提升性能,但我們會在以后開展這項探究工作。 為了簡單性起見,并鑒于計算資源方面的限制,我們為XLM-R使用了25萬個單詞的詞匯量。 ”
單詞是一個計算問題,因為使用更多的單詞需要將模型的更多參數專用于神經網絡的輸入層,在輸入層將單詞嵌入為向量,而這意味著從網絡的其他部分獲取一些有限的參數容量。
XLM-R這個例子表明了深度學習領域的兩個重要趨勢。 一個趨勢是,科學家們仍一心想構建越來越大的語言模型,以獲得更好的基準測試結果。
而那些科學家繼續遇到計算容量方面的瓶頸。 這是表明如果計算界要支持科學家們想要完成的事情,就不得不改變的另一個跡象。
特別聲明:
文章來源:云頭條
原文鏈接:https://mp.weixin.qq.com/s/pDdfOOG-nO6k4Sr4cXZxhg
RPA中國推薦閱讀,轉載此文是出于傳遞更多信息之目的。如有來源標注錯誤或侵權,請聯系更正或刪除,謝謝。
繼續閱讀:AI Facebook
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > Facebook最新的龐大語言AI遭遇計算瓶頸,哪怕使用500個英偉達GPU!


heng.png)
 達觀助手智能寫作產品正式發布,全面提升寫作能力!
達觀助手智能寫作產品正式發布,全面提升寫作能力! 生成式AI為何不完全適用當下B2B行業?
生成式AI為何不完全適用當下B2B行業? Gartner:ChatGPT只是開始,企業生成式AI的未來
Gartner:ChatGPT只是開始,企業生成式AI的未來 ?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望
?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望















熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國