

近日,Uber宣布開源其AI模型調試工具Manifold,這是一款與模型無關的可視化調試工具,可幫助工程師和科學家跨ML數據切片和模型識別潛在問題,并通過顯示數據子集之間的特征分布差異來診斷其根本原因。

通常當數據科學家開發AI模型時會使用匯總得分,例如:對數損失、曲線下面積(AUC)和平均絕對誤差(MAE)來評估每個候選AI模型。盡管這些指標提供了有關模型執行情況的見解,但它們并未傳達有關模型執行不佳的原因,以及如何改善模型性能的大量信息。
因此,模型構建者在確定如何改進其模型時傾向于依靠反復試驗。為了使模型迭代過程更明智和可操作,Uber開發了Manifold用于ML性能診斷和模型調試。利用可視化分析技術,Manifold使ML從業人員可以快速看到用于測試的AI模型缺點以及改進方式。
Manifold利用所謂的聚類算法(k-Means)將預測數據,根據其性能相似性分成多個段。該算法通過其KL散度對特征進行排名,KL散度是兩個對比分布之間差異的度量。一般而言,在Manifold中,較高的發散度表示給定的特征與區分兩個片段組的因子相關。
Manifold包括對多種算法類型的支持,包括常規的二進制分類和回歸模型。在可視化方面,它可以提取數字和分類以及地理空間要素類型。它與Jupyter Notebook集成在一起,Jupyter Notebook是為數據科學家和ML工程師使用最廣泛的數據科學平臺之一,并且具有交互式數據切片和基于每個實例的預測損失和其他特征值的性能比較。
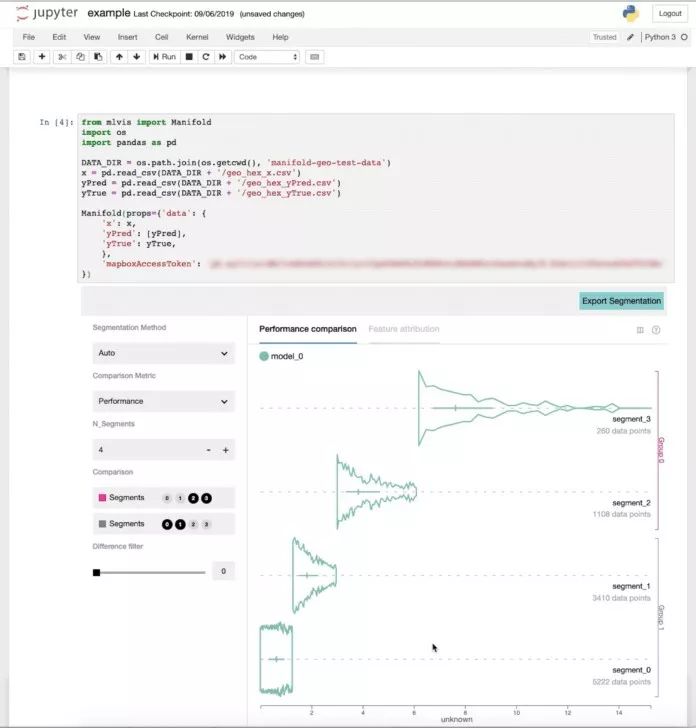
Uber還添加了各種功能在Manifold中,使AI模型的調試過程更加容易,功能如下:
-
支持與模型無關的通用二進制分類和回歸模型調試:用戶可以分析和比較各種算法類型的AI模型,從而使他們能夠區分各種數據片的性能差異。
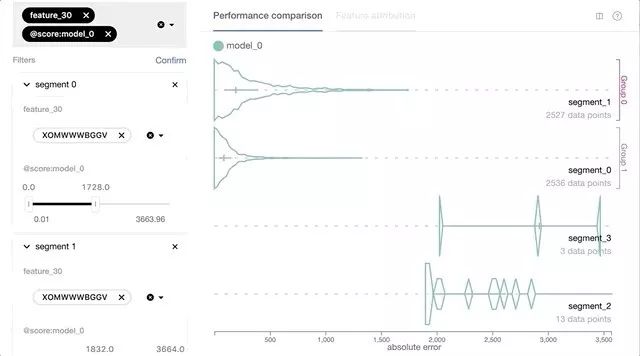
-
對表格化要素輸入的可視化支持,包括數字,分類和地理空間等類型:通過每個數據切片的特征值分布信息,使用戶可以更好地了解某些性能問題的潛在原因,例如:模型的預測損失與其數據點的地理位置和分布之間是否存在關聯。
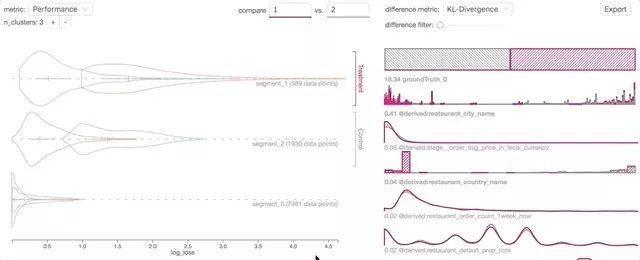
-
與Jupyter Notebook集成:通過這種集成,Manifold將數據輸入作為Pandas DataFrame對象接受,并在Jupyter中呈現此數據的可視化。由于Jupyter Notebook是數據科學家和ML工程師使用最廣泛的數據科學平臺之一,因此該集成使用戶可以在不中斷正常工作流程的情況下分析其AI模型。
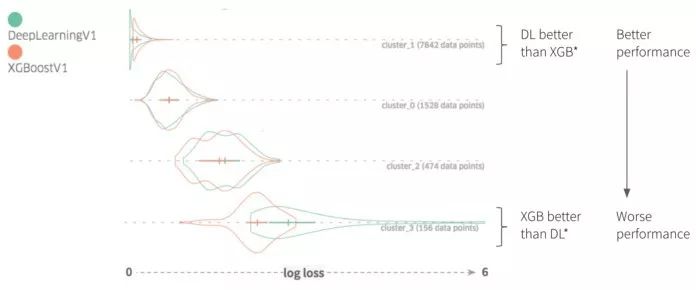
-
基于每個實例的預測損失和其他特征值的交互式數據切片與性能比較:用戶將能夠基于預測損失、地面真實性或其他感興趣的特征對數據進行切片和查詢。該功能將使用戶能夠通過通用的數據切片邏輯快速驗證或拒絕其假設。
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > Uber開源Manifold,一款可視化AI模型調試工具
heng.png)
 達觀助手智能寫作產品正式發布,全面提升寫作能力!
達觀助手智能寫作產品正式發布,全面提升寫作能力! 生成式AI為何不完全適用當下B2B行業?
生成式AI為何不完全適用當下B2B行業? Gartner:ChatGPT只是開始,企業生成式AI的未來
Gartner:ChatGPT只是開始,企業生成式AI的未來 ?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望
?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望















熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國