

大型語言模型在內容生成、邏輯推理等方面展示了強大的能力,但在處理專業幾何數學難題時效果不佳。
這是因為,與文本數學題相比,幾何空間數學題對模型的視覺理解和邏輯思維能力更高要求。目前,多模態大語言模型仍無法準確解析幾何圖形中的基本要素及其關系。
為了解決這一難題,華為諾亞方舟實驗室、香港大學、香港科技大學聯合開源了專業幾何數學模型G-LLaVA。
為了測試G-LLaVA的性能,研究人員在知名數學測試平臺 MathVista上,與其他大模型進行了深度評估。結果顯示,G-LLaVA的性能超過了GPT-4-V、LLaVA1.5、MiniGPT-4等模型。
開源地址:https://github.com/pipilurj/G-LLaVA
論文地址:https://arxiv.org/abs/2312.11370

整體架構
G-LLaVA的整體架構主要包含大語言模型、圖像編碼器和投影層三大模塊。
1)大語言模型使用的是LlAMA模型,用于理解和生成文字序列。相比通用模型,G-LLaVA的語言模型通過幾何數據獲得了數學和視覺領域的適配。
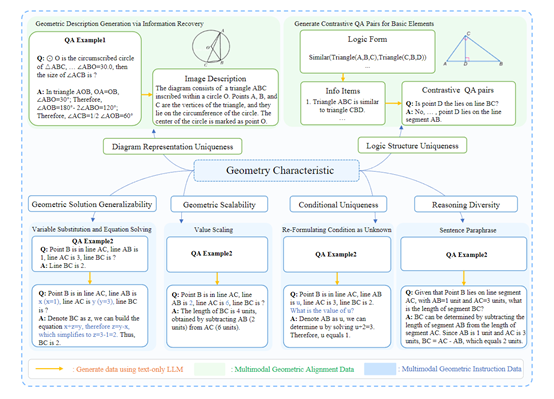
2)圖像編碼器利用預訓練的視覺ViT等,進行特征提取和圖像理解,可將輸入的幾何圖像和問題轉化為向量表示并生成答案。
3)投影層是一個線性層,作用是將圖像編碼器輸出的視覺特征投影和映射到語言模型的嵌入空間中。這實現了不同模態特征的對齊融合,讓大語言模型可以識別幾何圖像的關鍵所在。
訓練方法
G-LLaVA使用的是雙階段漸進式訓練方法:幾何視覺語言對齊,這一階段專注于增強模型對幾何圖像的理解,令其準確解釋幾何圖形基本要素。
構建的對齊數據集包含圖像描述和判斷對比問答。只優化投影層參數進行對齊訓練。

幾何指令調優,在調整階段,利用變量建模、數據增強等策略生成大規模幾何問題解答數據。通過解題過程的復現,提高G-LLaVA的數學建模建、關系、符號推理的能力。調優后的模型可接收幾何圖像和自然文本提示并輸出內容。
構建Geo170K數據集
G-LLaVA能具備強大的幾何理解能力,這個Geo170K數據集是關鍵。
Geo170K的數據來源包括多個已有的開源幾何QA數據集,例如,Geometry3K、GeoQA和GeoQA+。
這些數據集提供了豐富的幾何圖像樣例和部分注釋, Geo170K的總規模超過17萬條。
包含約6萬張幾何圖像及匹配描述,和11萬多個問題-解答語言配對。這遠超過此前最大的圖形問答集GeoQA+。數據分布覆蓋了基本幾何要素的判定、定量關系的符號推理等多個方面。
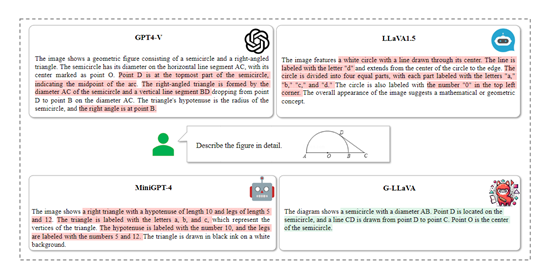
為了評估G-LLaVA的性能,研究人員在MathVista等測試平臺進行了一系列實驗,與其他現有的知名大語言模型進行了比較。
實驗結果顯示,G-LLaVA與GPT-4-V和其他MLLMs相比,G-LLaVA的性能超過了GPT-4-V、LLaVA1.5、MiniGPT-4等模型。顯著提高了幾何難題的解決準確率和效率。
這表明通過引入對齊的多模態數據集,可以有效地提升大語言模型在處理幾何問題時的能力。
此外,研究人員還對G-LLaVA模型進行了進一步的分析,以探索其在各個幾何問題類型上的性能差異。
實驗結果顯示,G-LLaVA模型在處理點、線、角等基本幾何元素的問題時表現仍然出色。
本文素材來源G-LLaVA論文,如有侵權請聯系刪除
END
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > 性能優于GPT4-V,華為、港大開源幾何數學模型G-LLaVA
heng.png)
 達觀助手智能寫作產品正式發布,全面提升寫作能力!
達觀助手智能寫作產品正式發布,全面提升寫作能力! 生成式AI為何不完全適用當下B2B行業?
生成式AI為何不完全適用當下B2B行業? Gartner:ChatGPT只是開始,企業生成式AI的未來
Gartner:ChatGPT只是開始,企業生成式AI的未來 ?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望
?中國何時能有ChatGPT?“現象級”產品背后的AI技術發展與展望













熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國