

微軟亞洲研究院、中國科學(xué)院自動化研究所、中國科學(xué)技術(shù)大學(xué)和卡內(nèi)基梅隆大學(xué)聯(lián)合開源了,用于評估、分析大語言模型的統(tǒng)一測試平臺——PromptBench。
Prompt Bench支持目前主流的開源、閉源大語言模型,例如,ChatGPT、GPT-4、Phi、Llma1/2、Gemini、Baichuan、Yi 等。
PromptBench內(nèi)置了豐富的評估工具,包括提示構(gòu)建、提示工程、數(shù)據(jù)集和模型、對抗性提示攻擊、性能評測等。用戶可以根據(jù)實際開發(fā)情況靈活配置,非常簡單高效。
開源地址:https://github.com/microsoft/promptbench
論文地址:https://arxiv.org/abs/2312.07910
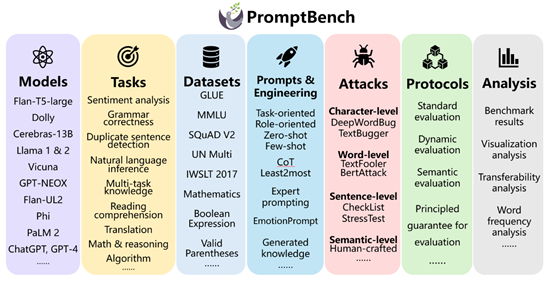
對大型語言模型進行評估、分析是理解其真實輸出、減少潛在風(fēng)險的重要開發(fā)環(huán)節(jié)。
研究人員表示,目前多數(shù)大型語言模型對文本提示非常敏感,容易受到對抗性提示攻擊,同時易受到數(shù)據(jù)污染的影響,這給安全和隱私帶來了巨大挑戰(zhàn)。
雖然有很多類似lm-eval-harness的評估框架,但其評估模塊和功能較少,無法滿足飛速發(fā)展的大語言模型領(lǐng)域。
所以,微軟等研究人員希望開發(fā)一個統(tǒng)一的評估平臺,幫助開發(fā)者提升測試效率,同時減少大模型的非法內(nèi)容輸出。
PromptBench簡單介紹
PromptBench可以從多個維度對大語言模型進行評估,涵蓋多個任務(wù)、評估協(xié)議、對抗性提示攻擊和提示工程技術(shù)、數(shù)據(jù)集等。
評估協(xié)議是PromptBench的核心模塊之一,主要定義了評估大語言模型性能的方法和流程。
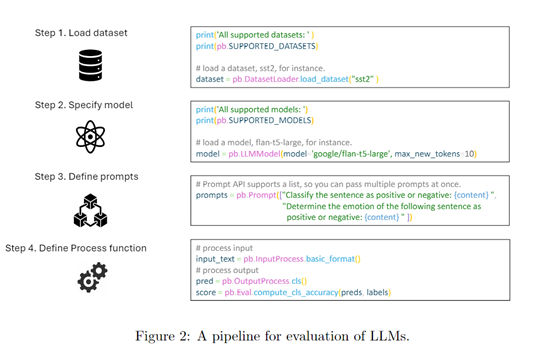
PromptBench支持多種評估協(xié)議,包括靜態(tài)評估和動態(tài)評估。靜態(tài)評估是,通過提供預(yù)定義的提示來測試大語言模型的性能;
動態(tài)評估,則允許在交互過程中動態(tài)生成和修改提示。這種靈活性使研究人員能夠更全面地評估大語言模型的能力和魯棒性。
對抗性提示攻擊,是評估大語言模型安全性的重要方法之一。PromptBench提供了多種對抗性提示攻擊的測試方法,包括,字符級修改、詞級替換、句級添加和語義級改寫等攻擊。有效模擬了提示使用中可能遇到的各類偏差情況,檢驗了模型的攻擊魯棒性。
數(shù)據(jù)集是評估大語言模型性能的關(guān)鍵部分。PromptBench提供了20多個公開的評估數(shù)據(jù)集,涵蓋了文本分類、語法糾錯、句子相似度判定、自然語言推理、多任務(wù)問答、閱讀理解、翻譯、數(shù)學(xué)推理、邏輯推理等,可以充分測試大語言模型在不同場景下的表現(xiàn)和能力。
支持哪些大語言模型
PromptBench支持目前市面上主流的開源、閉源大語言模型,包括Flan-T5-large、Dolly系列、Cerebras-13B 、Llama系列、Vicuna 、GPT-NEOX;
Flan-UL2、Phi 、PaLM 2、ChatGPT、GPT-4、Gemini、Mistral、Mixtral、Baichuan、Yi等。
研究人員表示,未來會持續(xù)更新對大語言模型的支持,將打造成一個涵蓋模型最多、評估功能最全的統(tǒng)一測試平臺。
本文素材來源PromptBench論文,如有侵權(quán)請聯(lián)系刪除
未經(jīng)允許不得轉(zhuǎn)載:RPA中國 | RPA全球生態(tài) | 數(shù)字化勞動力 | RPA新聞 | 推動中國RPA生態(tài)發(fā)展 | 流 > 微軟等開源評估ChatGPT、Phi、Llma等,統(tǒng)一測試平臺
heng.png)
 達觀助手智能寫作產(chǎn)品正式發(fā)布,全面提升寫作能力!
達觀助手智能寫作產(chǎn)品正式發(fā)布,全面提升寫作能力! 生成式AI為何不完全適用當下B2B行業(yè)?
生成式AI為何不完全適用當下B2B行業(yè)? Gartner:ChatGPT只是開始,企業(yè)生成式AI的未來
Gartner:ChatGPT只是開始,企業(yè)生成式AI的未來 ?中國何時能有ChatGPT?“現(xiàn)象級”產(chǎn)品背后的AI技術(shù)發(fā)展與展望
?中國何時能有ChatGPT?“現(xiàn)象級”產(chǎn)品背后的AI技術(shù)發(fā)展與展望















熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發(fā)者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發(fā)展洞察(2022)》報告正式發(fā)布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰(zhàn)賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產(chǎn)業(yè)共進,第四屆ISIG中國產(chǎn)業(yè)智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業(yè)研究報告》正式發(fā)布 | RPA中國