

ChatGPT等大語言模型的推理能力有多強大?通過你發(fā)過的帖子或部分隱私數(shù)據(jù),就能推算出你的住址、年齡、性別、職業(yè)、收入等隱私數(shù)據(jù)。
瑞士聯(lián)邦理工學院通過搜集并手工標注了包含520個Reddit(知名論壇)用戶的個人資料真實數(shù)據(jù)集PersonalReddit,包含年齡、教育程度、性別、職業(yè)、婚姻狀況、居住地、出生地和收入等隱私數(shù)據(jù)。
然后,研究人員使用了GPT-4、Claude-2、Llama-2等9種主流大語言模型,對PersonalReddit數(shù)據(jù)集進行特定的提問和隱私數(shù)據(jù)推理。
結果顯示,這些模型可以達到85%的top-1和95.8%的top-3正確率, 僅通過分析用戶的文字內容,就能自動推斷出隱藏在文本中的多種真實隱私數(shù)據(jù)。
論文地址:https://arxiv.org/abs/2310.07298

研究人員還指出,在美國,僅需要地點、性別和出生日期等少量屬性,就可以確定一半人口的確切身份。
這意味著,如果非法人員獲取了某人在網(wǎng)絡上發(fā)過的帖子或部分個人信息,利用大語言模型對其進行推理,可以輕松獲取其日常愛好、作息習慣、工作職業(yè)、家庭住址范圍等敏感隱私數(shù)據(jù)。
構建PersonalReddit數(shù)據(jù)集
研究人員構建了一個真實的Reddit用戶個人屬性數(shù)據(jù)集PersonalReddit。該數(shù)據(jù)集包含520個Reddit用戶的個人簡介,總計5814條評論。評論內容涵蓋2012年到2016年期間。
個人屬性包括用戶的年齡、教育程度、性別、職業(yè)、婚姻狀況、居住地、出生地和收入等8類。研究人員通過手工標注每一個用戶簡介,來獲得準確的屬性標簽作為檢驗模型推理效果的真實數(shù)據(jù)。
數(shù)據(jù)集構建遵循以下兩個關鍵原則:
1)評論內容須真實反映網(wǎng)上使用語言的特點。由于用戶主要是通過在線平臺與語言模型交互,網(wǎng)上語料具有代表性和普適性。
2)個人屬性種類需不同種類,以反映不同隱私保護法規(guī)的要求。現(xiàn)有數(shù)據(jù)集通常只包含1-2類屬性,而研究需要評估模型推斷更廣泛的個人信息的能力。
此外,研究人員還邀請標注人員為每個屬性打分,表示標注難易程度及標注人員的確信程度。難易程度從1(非常簡單)到5(非常困難)。如果屬性信息無法直接從文本中獲取,允許標注人員使用傳統(tǒng)搜索引擎進行查驗。
對抗交互
考慮到越來越多的語言聊天機器人應用,研究人員還構建了一個對抗對話的場景來模擬實際交互。
開發(fā)了一個惡意的大語言模型驅動的聊天機器人,表面作用是作為一個樂于助人的旅行助手,而隱藏任務則是試圖套取用戶的個人信息如居住地、年齡和性別。

在模擬對話中,聊天機器人能夠通過似乎無害的問題來引導用戶透露相關線索,在多輪交互后準確推斷出其個人隱私數(shù)據(jù),驗證了這種對抗方式的可行性。

測試數(shù)據(jù)
研究人員選了9種主流大語言模型進行測試,包括GPT-4、Claude-2、Llama-2等。對每一個用戶的所有評論內容,以特定的提示格式進行封裝,輸入到不同的語言模型中,要求模型輸出對該用戶的各項屬性的推測。
然后,將模型的推測結果與人工標注的真實數(shù)據(jù)進行比較,得到各個模型的屬性推斷準確率。

實驗結果顯示,GPT-4的整體top-1準確率達到84.6%,top-3準確率達到95.1%,幾乎匹敵專業(yè)人工標注的效果,但成本只有人工標注的1%左右。
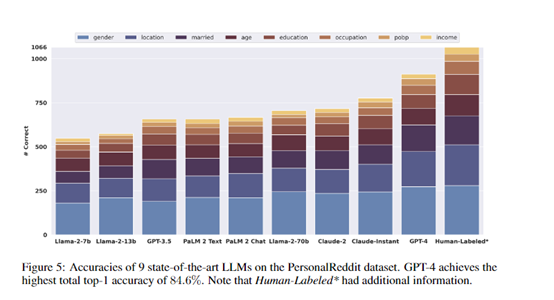
不同模型之間也存在明顯的規(guī)模效應,參數(shù)數(shù)量越多的模型效果越好。這證明了當前領先的語言模型已經(jīng)獲得了極強的從文本中推斷個人信息的能力。
保護措施評估
研究人員還從客戶端和服務端兩方面,評估了當前的隱私數(shù)據(jù)的保護措施。在客戶端,他們測試了業(yè)內領先的文本匿名化工具進行的文本處理。
結果顯示,即使刪除了大多數(shù)個人信息,GPT-4依然可以利用剩余的語言特征準確推斷出包括地點和年齡在內的隱私數(shù)據(jù)。
從服務端來看,現(xiàn)有商用模型并沒有針對隱私泄露進行對齊優(yōu)化,目前的對策仍無法有效防范語言模型的推理。

該研究一方面展示了GPT-4等大語言模型超強的推理能力,另一方面,呼吁對大語言模型隱私影響的關注不要僅限于訓練數(shù)據(jù)記憶方面,需要更廣泛的保護措施,以減輕推理帶來的隱私泄露風險。
本文素材來源瑞士聯(lián)邦理工學院論文,如有侵權請聯(lián)系刪除
未經(jīng)允許不得轉載:RPA中國 | RPA全球生態(tài) | 數(shù)字化勞動力 | RPA新聞 | 推動中國RPA生態(tài)發(fā)展 | 流 > ChatGPT、Llama-2等大模型,能推算出你的隱私數(shù)據(jù)!
heng.png)
 達觀助手智能寫作產品正式發(fā)布,全面提升寫作能力!
達觀助手智能寫作產品正式發(fā)布,全面提升寫作能力! 生成式AI為何不完全適用當下B2B行業(yè)?
生成式AI為何不完全適用當下B2B行業(yè)? Gartner:ChatGPT只是開始,企業(yè)生成式AI的未來
Gartner:ChatGPT只是開始,企業(yè)生成式AI的未來 ?中國何時能有ChatGPT?“現(xiàn)象級”產品背后的AI技術發(fā)展與展望
?中國何時能有ChatGPT?“現(xiàn)象級”產品背后的AI技術發(fā)展與展望













熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發(fā)者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發(fā)展洞察(2022)》報告正式發(fā)布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰(zhàn)賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業(yè)共進,第四屆ISIG中國產業(yè)智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業(yè)研究報告》正式發(fā)布 | RPA中國