

項籍是下相人,字羽。開始起事的時候,他二十四歲。項籍的叔父是項梁,項梁的父親是項燕,就是被秦將王翦所殺害的那位楚國大將。項氏世世代代做楚國的大將,被封在項地,所以姓項。
(原文:項籍者,下相人也,字羽。初起時,年二十四。其季父項梁,梁父即楚將項燕,為秦將王翦所戮者也。項氏世世為楚將,封于項,故姓項氏。)

-
姓名:項籍/項羽
-
籍貫:下相(今江蘇宿遷)
-
出道:24歲
-
叔父:項梁
-
叔父的爹(爺爺):項燕
-
仇家:秦國 王翦
-
姓氏由來:項家世世代代為楚國大將,被封在項地,所以姓項
現在請在20秒時間內看一下上面的信息并給別人介紹一下項羽,可以選擇看原文,也可以選擇看提取之后的信息。相信很多人會選擇看后一種。這是因為后一種行文方式其核心信息不丟失,但是內容更簡練,邏輯性更強,更容易記憶。這就是信息提取的意義。接下來的篇章將用更通俗的方式介紹一下文本信息提取技術的產業應用。
信息披露是金融改革發展的長期趨勢。從2018年4月的資管新規發布,再到2019年的科創板和注冊制。信息披露一直是監管層強調的重點。以上市公司為例,需要披露的信息包括首次披露(IPO招股說明書),定期報告(年度報告、中期報告、季度報告)和臨時報告等多種文檔。隨著上市企業的不斷增多和信息披露機制的不斷加強,給監管層、資本市場、普通投資者都帶來了新的壓力。對監管層來說,信息披露的審核量加大;對資本市場和投資者來說,投研要求更高,對企業的分析從個體的財務經營狀況到產業鏈競爭力,不一而足。
下圖是達觀數據文檔智能審閱系統(以下簡稱:IDPS)對招股書進行提取的示例,通過將文檔上傳到文檔智能審閱系統中,一份大幾百頁的招股書被快速提取成右邊上千個核心要素,包括董監高信息、財務信息、專利情況、募集資金與應用、上下游企業、重大合同、發行人所處行業等。同時支持點擊跳轉功能,比如點擊右側董事基本情況,除了直接提取出董事的姓名、出生年月、國籍、學歷等信息外,左側窗口頁面也會滾動到招股書原文的對應位置。
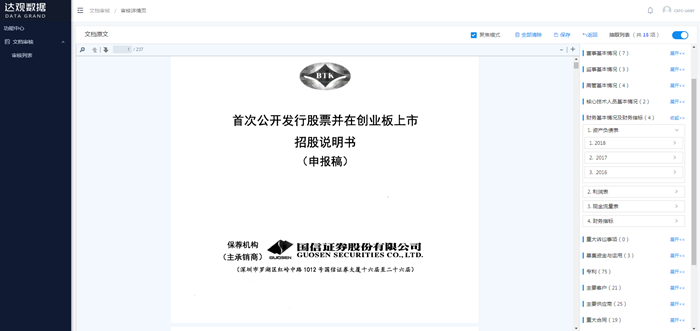
圖1 利用IDPS對招股書進行提取
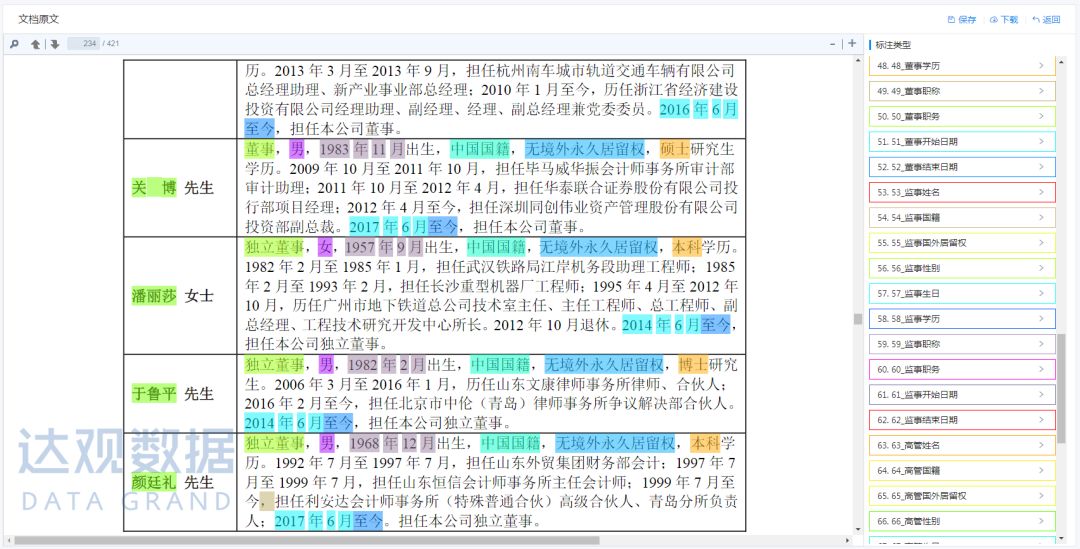
圖2 利用IDPS對招股書中董監高信息進行提取

圖3 利用IDPS表格提取對PDF格式的財報進行提取
你可能會問,企業的經營狀況尤其是財務狀況在其公告中都有非常詳細的報表(資產負債表,利潤表,現金流量表),為什么還要做提取呢?這是因為信息提取解決的并不是有與無的問題,而是解決效率和標準的問題,比如同樣是2018年的上市財報,各家的格式、排版都不一樣。所以人工閱讀一份財報了解一家企業的基本面狀況,同樣的時間,借助信息提取了解的可能是一個行業幾十家企業的基本面狀況。這種有效信息量的巨大差異,對于投資決策的影響必定不同,帶來的投資回報一定也是不一樣的。
你可能還會問,能否自上到下推廣一套統一的財報標準,所有企業都按照這個標準來披露財務狀況,這樣就不會有“代溝”了。其實行業內已經存在了,這里補充一個小插曲。
XBRL,1998年美國人提出,被譽為財務報表領域內的條形碼。XBRL是在XML的基礎上發展而來的,專門用于財務報告編制、披露和使用的計算機語言。XBRL通過對商業報告中的數據增加特定的標簽和分類標準,以支持數據信息的識別、處理與交流。XBRL主要由技術規范、分類標準和實例文檔三部分組成。技術規范是XBRL的總綱,定義了各類專業術語,規范XBRL文檔結構。分類標準是根據XBRL技術規范對商業報告中的元素及其關系進行標記和描述的“業務詞典”,是編制XBRL實例文檔的具體規范。XBRL實例文檔是依據前兩個制作的實際財務或商業數據文件,是XBRL數據的載體。
在 XBRL 推出前,財務信息披露的數據格式包括 TXT、PDF、WORD、EXCEL等。這些財務數據披露格式很難實現不同形式數據間自由轉換的功能,從而增加了信息使用者對信息對比分析的難度。XBRL打破了這一瓶頸,為財務信息提供了一個統一的標準化格式,可以實現財務信息的跨空間、跨時間對比。
在我國,XBRL推廣主要包括證監會和財政部。證監會在上市公司財報披露,財政部在大型國資企業信息披露都有試點。但截止到目前,XBRL真正的潛力和作用并沒有被完全發揮。這其中的原因較為復雜,從設立標準角度看,建立一套接軌國際同時滿足行業、地域、監管要求的標準何其難;從推廣使用角度看,上市公司、資本市場尚未對XBRL有足夠的重視。所以,盡管大家都能理解XBRL是個好東西。但是要到普遍的推廣應用,還有很長的道路要走。
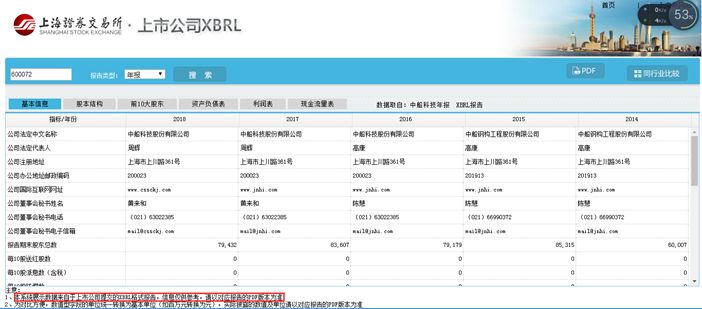
證監會是XBRL在國內最早的推廣者。上證交易所官網有利用XBRL披露上市公司年報。但在網頁下方會提示:“本系統展示數據來自于上市公司提交的XBRL格式報告,信息僅供參考,請以對應報告的PDF版本為準”。
2014年,最高人民法院為貫徹落實審判公開原則,促進司法公正,提升司法公信力,發布了《關于人民法院在互聯網公布裁判文書的規定》,除涉及國家秘密、未成年人犯罪等少數幾類判決文書不公布外,其余判決文書都需要在互聯網上公開。(最高法裁判文書網,http://wenshu.court.gov.cn/)。
同提取金融領域披露的信息公告一樣,也可以對公布的判決文書進行信息提取。比如針對一份民事判決書,我們可以提取案號、案由、審級、原被告、代理律師、代理律所、依據法律、審判機關、判決日期、判決結果等上百個核心要素信息。
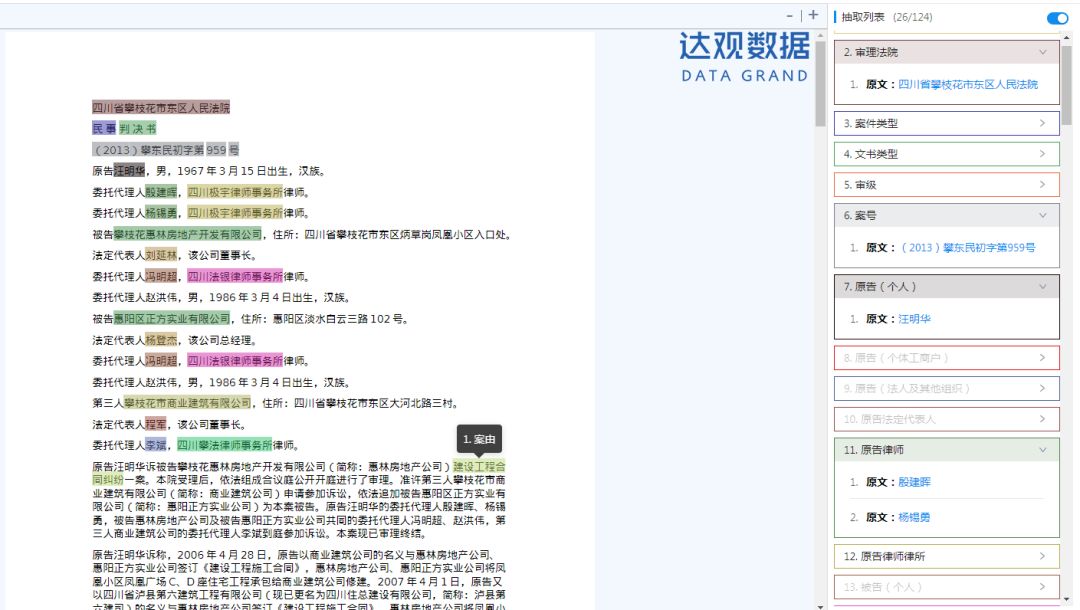
圖4 利用達觀IDPS提取民事判決文書中的要素
那么對法律判決文書的信息提取又有什么用呢?當我們對數千萬份判決文書進行信息提取之后,我們閱讀判決文書的視角,就從單份文書縱向閱讀擴展到全量文書橫向閱讀。這種擴展會帶來的價值,還是通過幾個例子來說明。比如現在離婚率越來越高,若想了解最近三年各省離婚案件的整體情況,就可以在案件信息提取的基礎上,從時間、地域角度分析統計離婚案件的數量、判決結果、案由等,并進一步分析這種現狀產生的社會經濟因素;再比如我現在面臨一起專利糾紛,想找一位代理專利糾紛案件比較有經驗律師,就可以利用案由、律師、律所、判決結果這些要素去組合篩選出一位心儀的代理律師。
通過前文介紹,大概了解了信息提取這項技術的應用。接下來簡單介紹下這些技術的原理。
我們知道機器學習是已知一組自變量(input)和一組因變量(output),找到一個函數能夠最優地擬合這組input和output。當有新的input進入時,利用這個函數可以得出output。所以,機器學習就好比把大象裝冰箱,只需要三步。
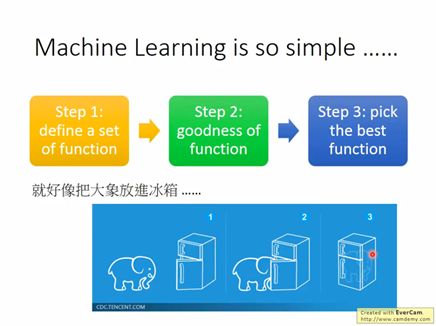
如何利用機器學習去做信息提取呢,常用的就是序列標注。序列標注簡單講就是選用一些標簽對輸入的序列數據進行標簽化。比如我想提取6月25日美空軍戰斗機在東地中海上空開展編隊飛行這個事件中的時間和地點。選用BMEO(Begin, Middle, End, Other)來標記,BMEO每一個字母代表一個單字,一個詞由多個單字組成,所以B代表中文單詞的第一個漢字,M代表單詞中間的漢字,E代表單詞最后的漢字,用O代表其他不需要提取的字。我用T代表時間(此時T_B代表時間的第一個字,T_M代表時間中間的字,T_E代表時間最后的字)。用L代表地點(此時L_B代表地點的第一個字,L_M代表地點中間的字,L_E代表地點最后的字)。
信息提取解決的并不是信息的有和無問題,而是解決效率和標準的問題。它用更加效率的方式將信息重新整合成一種標準規范的方式,從而用一個更為寬廣的視角去審閱這些信息。
特別聲明:
文章來源:達觀數據(Datagrand_)
作者: 呂文超:達觀數據解決方案架構師,負責達觀推薦引擎,搜索引擎,NLP,RPA等AI產品和技術在金融、軍工、政府、互聯網等行業的應用落地。
原文鏈接:https://mp.weixin.qq.com/s/Hy-ggE_FmIb9LctL0YHAzw
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > 如何應用信息提取技術做好金融和法律文檔的結構化處理?
heng.png)
 RPA CoE x GPT = 未來企業
RPA CoE x GPT = 未來企業 RPA技術的進階之路:智能化、多元化與增強發展
RPA技術的進階之路:智能化、多元化與增強發展 沒錢沒需求,企業數字化轉型怎么干?
沒錢沒需求,企業數字化轉型怎么干? 從ChatGPT數據泄露事件,看組織安全穩定自動化的重要性
從ChatGPT數據泄露事件,看組織安全穩定自動化的重要性













熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國