

隨著ChatGPT等模型被廣泛應用,用戶對功能的需求也呈多模態(tài)發(fā)展,例如,在單一模型上既能生成文本也可以生成圖片等。
但現(xiàn)有視覺模型通常僅針對單一模態(tài)和任務(wù)進行優(yōu)化,缺乏能夠處理多種模態(tài)和任務(wù)的通用能力。
為了解決這一難題,蘋果的研究人員和全球著名公立大學EPFL(瑞士洛桑聯(lián)邦理工學院)聯(lián)合開發(fā)了4M框架并即將開源。4M可以把多種輸入/輸出模態(tài),包括文本、圖像、幾何、語義模態(tài)以及神經(jīng)網(wǎng)絡(luò)特征圖等,全部集成在大模型中(適用于Transformer架構(gòu))。
項目地址:https://4m.epfl.ch/
論文地址:https://arxiv.org/abs/2312.06647

4M技術(shù)原理簡單介紹
相比以往單一模態(tài)下的深度學習方法,4M最大的技術(shù)亮點在于使用了一種名為"Massively Multimodal Masked Modeling"(大規(guī)模多模態(tài)屏蔽建模)的訓練方法。
可以同時處理圖像、語義、幾何等各類視覺模態(tài),將影像、字幕、框架信息等,都能以離散 tokens 的形式完美“翻譯”出來,實現(xiàn)各模態(tài)在表示空間上的統(tǒng)一。
為確保tokens之間協(xié)調(diào)一致,4M還在注意力機制中加入模態(tài)區(qū)分,禁止不同模態(tài)之間互相影響。同時4M訓練采用掩碼重建目標,實際上相當于進行模態(tài)間的預測編碼。
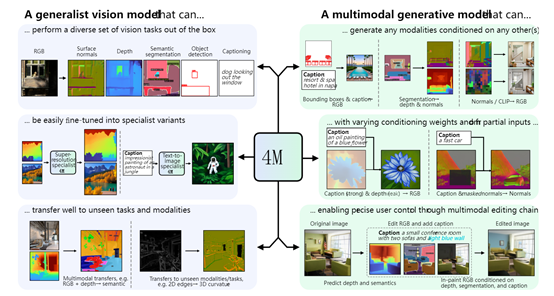
在訓練過程中,模型會隨機選擇一小部分標記作為輸入,另一小部分標記作為目標,通過解耦輸入和目標標記的數(shù)量與模態(tài)數(shù)量的關(guān)系,實現(xiàn)了可擴展的訓練目標。
簡單來說,無論用戶輸入的內(nèi)容是圖片還是文本,對于4M來說都是一串標準化的數(shù)字標記。這種“通用語言”設(shè)計有效阻斷了各模態(tài)特有信息對模型架構(gòu)的影響,極大提升了模型的通用性。
訓練數(shù)據(jù)和方法
4M將在訓練過程中使用了全球最大的開源數(shù)據(jù)集之一CC12M,包含圖像、深度圖、語義信息、文本等各類數(shù)據(jù)集。
雖然CC12M的數(shù)據(jù)很多,但缺乏準確的標注信息。為了解決這個難題,研究人員使用了一種高效、成本又低的方法——弱監(jiān)督偽標簽。這個與前幾天OpenAI開源的超級對齊方法很相似。
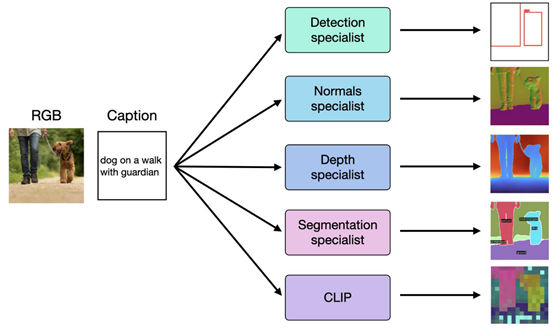
通過利用CLIP、MaskRCNN等技術(shù),對CC12M的圖像數(shù)據(jù)集進行全面預測,然后得到語義、幾何及視覺特征等豐富模態(tài)信息。
再使用轉(zhuǎn)換“翻譯”模塊將所有偽標簽信息,統(tǒng)一轉(zhuǎn)化為離散表示的“tokens”。這為4M在不同模態(tài)之間實現(xiàn)統(tǒng)一的兼容奠定基礎(chǔ)。
研究人員在廣泛的實驗和基準測試平臺中對4M進行了測試,可以直接執(zhí)行多模態(tài)任務(wù),而無需進行大量的特定任務(wù)預訓練或微調(diào)。
本文素材來源4M論文,如有侵權(quán)請聯(lián)系刪除
未經(jīng)允許不得轉(zhuǎn)載:RPA中國 | RPA全球生態(tài) | 數(shù)字化勞動力 | RPA新聞 | 推動中國RPA生態(tài)發(fā)展 | 流 > 可將任意大模型實現(xiàn)多模態(tài),蘋果開源4M
heng.png)
 達觀助手智能寫作產(chǎn)品正式發(fā)布,全面提升寫作能力!
達觀助手智能寫作產(chǎn)品正式發(fā)布,全面提升寫作能力! 生成式AI為何不完全適用當下B2B行業(yè)?
生成式AI為何不完全適用當下B2B行業(yè)? Gartner:ChatGPT只是開始,企業(yè)生成式AI的未來
Gartner:ChatGPT只是開始,企業(yè)生成式AI的未來 ?中國何時能有ChatGPT?“現(xiàn)象級”產(chǎn)品背后的AI技術(shù)發(fā)展與展望
?中國何時能有ChatGPT?“現(xiàn)象級”產(chǎn)品背后的AI技術(shù)發(fā)展與展望















熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發(fā)者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發(fā)展洞察(2022)》報告正式發(fā)布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰(zhàn)賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產(chǎn)業(yè)共進,第四屆ISIG中國產(chǎn)業(yè)智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業(yè)研究報告》正式發(fā)布 | RPA中國