


視頻、語音、文本是拉動人工智能發展的三駕馬車,但是,相比視頻和語音,文本智能處理更難突破。成立于2015年的達觀數據是一家專注于文本智能處理的公司,基于自然語言處理、知識圖譜等技術,為客戶提供文本自動抽取、審核、糾錯、搜索、推薦、寫作等智能軟件系統,實現業務流程自動化,提高企業效率。近日,達觀數據CEO陳運文博士向億歐分享了文本智能處理技術和應用現狀。
文本挖掘工作一半是技術一半是藝術
在人類過去大概100萬年的進化過程中,人類文明迭代速度很慢,但文字的出現使其陡然加速,為人類文明帶來了光和熱。隨著技術的發展,文字處理工作也由人工轉化為計算機。文本挖掘工作經歷了第一代符號主義、第二代語法規則、第三代統計學習,目前處于第四代深度學習階段,將實現用一個復雜的模型模擬人腦神經網絡運作。
在文本挖掘技術上,達觀數據一直走在行業前沿。達觀數據文檔審核系統2.0在深度學習的基礎上采用了遷移學習和增強學習,可實現注意力模型、BERT模型等,這也被稱為4.5代技術。陳運文表示,4.5代技術的使用可以加強機器的泛化能力,即提高機器對于文字的自適應理解能力或者說舉一反三能力,這將大大縮減訓練成本。
陳運文認為:“文本挖掘工作,一半是技術,一半是藝術。”文本挖掘工作需要慢工出細活,通過對文字的深入理解來探討如何使用數學模型更好的進行文字解讀。但是,從數學模型角度來講,很多時候文字的運用是不符合常理的。例如,“天很冷,能穿多少穿多少”和“天很熱,能穿多少穿多少”,同樣是“能穿多少穿多少”,但表達的是兩個意思。所以文本挖掘工作,它既是一個數學問題,通過后臺大量的數學運算對文字進行解讀,同時也需要將語言學等偏藝術領域的知識納入進去,才能讓計算機更好的解讀文字,甚至代替人完成一部分文字撰寫的工作。
NLP+RPA解放白領的手和腦
陳運文創業之前曾擔任盛大文學首席數據官、騰訊文學高級總監、百度核心技術研發工程師等職位,一直從事文本挖掘相關工作。他發現,工作中有60%左右的內容都是與文字相關,文字資料的處理和應用在互聯網企業內部雖然發揮了很大價值但沒有實現價值最大化。反而,在一些其他行業,人工智能技術應用還處于早期狀態,大量工作靠人手工記錄,NLP和RPA的結合將可以實現白領部分工作的自動化。
NLP (Natural Language Processing) ,自然語言處理可以讓計算機模擬白領的大腦運轉,實現閱讀和理解;RPA(Robotic Process Automation),機器人流程自動化可以模擬白領的手去進行鼠標和鍵盤的操作,實現自動化。如果只有RPA技術,計算機只能承擔初級的工作,但是有了NLP技術的幫助,就可以做更復雜的任務,真正承擔起虛擬員工的角色。
陳運文認為,NLP+RPA在中國大有可為,將是一片藍海市場。首先,技術走向成熟,國內RPA技術雖剛剛起步,但國外已經有許多成熟的應用。同時,UiPath、BluePrism等國外RPA企業也在通過不同的形式向中國市場滲透。其次,NLP+RPA可以明顯降低企業成本,帶來高回報率。根據IBM在《使用人工智能優化機器人流程自動化的價值》報告中的估算,通過RPA可實現 30% 到 50% 的投資回報率 (ROI)。最后,市場規模大。據《全球人工智能市場2017-2021》報告披露的數據,RPA的市場規模預計將在2024年達到50億美元,復合增長率達到61.3%。在亞太地區,RPA的市場規模預計在2021年達到8.17億美元,在此期間的增長率將達到181%。
金融行業是NLP+RPA落地的重要領域
NLP+RPA主要替代一些高重復、標準化、規則明確且高準確率要求的工作。金融行業過半員工在與文本合同打交道,但是他們90%的工作都是可以被替代的。
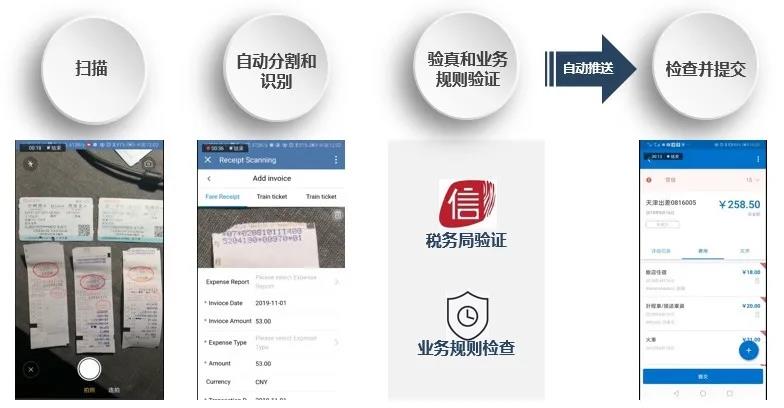
以信貸業務為例,貸前基于OCR可以幫助銀行工作人員對提交材料進行人物、事件、數值等關鍵信息抽取和審核;貸中支持合同多版本比對,對合同關鍵要素進行智能審核,防止陰陽合同風險;貸后對貸款項目評估報告關鍵信息提取及結構化,并對企業進行實時輿情分析監控,實現有效跟蹤和監督。
目前,達觀數據已服務招商銀行、中國平安、光大銀行等數十家金融機構。陳運文認為,金融行業對NLP+RPA的需求非常大,RPA具有非侵入性的特點,以外掛/插件的形式部署在客戶現有系統上,不影響其原有的成熟IT架構,部署成本較低。考慮到銀行的個性化定制需求,達觀在產品設計之初就特別重視產品的可擴展性。一方面,產品本身就支持客戶進行自定義規則,滿足自定制需求;另一方面,達觀也會不斷總結行業知識圖譜,升級產品,通過連接銀行內網的形式,幫助銀行升級語料庫和算法模型。
未來:文本智能處理專家
陳運文表示,我們將堅定的在文本智能處理這條路上走到頭,成為“文本智能處理專家”。2019年達觀數據一方面不斷積累海量的文本資料讓計算機訓練,另一方面不斷深挖現有的算法模型,重視基礎技術的研發工作。目前,達觀數據已與北京大學、復旦大學、上海財經大學等高校建立起了產學研合作關系,未來將與更多的高校合作,將學術界的先進成果與工程界的應用技術結合在一起,更好的突破文字語言理解工作
繼續閱讀:
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > 達觀數據陳運文:NLP+RPA潛力無窮,做文本智能處理專家
heng.png)
 來也科技汪冠春:大語言模型時代下,廣義RPA市場會是原來的100倍
來也科技汪冠春:大語言模型時代下,廣義RPA市場會是原來的100倍 金智維廖萬里:ChatGPT加持,RPA數字員工將迎來新發展階段
金智維廖萬里:ChatGPT加持,RPA數字員工將迎來新發展階段 靖亞資本任曉東:淺談工作自動化賽道的投資思考
靖亞資本任曉東:淺談工作自動化賽道的投資思考 高煜光:錨定RPA創新應用,打造超級自動化行業領軍者
高煜光:錨定RPA創新應用,打造超級自動化行業領軍者














熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國