

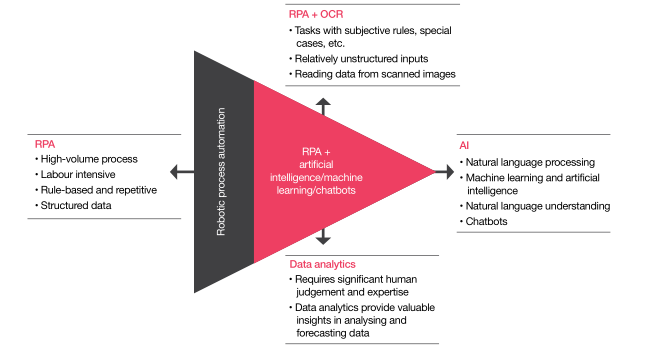
目前,全球各個行業都在謀求數字化轉型,以便更好的應對數字化經濟潮流,而RPA正成為其重要的轉型工具。隨著企業業務的多元化發展,多數已不僅僅滿足于傳統的自動化業務,開始轉向IPA(智能自動化)。
IPA是指將RPA與多種主流人工智能技術如OCR(光學字符識別)、ML(機器學習)、NLP(自然語言處理)等相結合的新型智能自動化。將幫助組織更好的處理那些非結構化數據任務,并且極大地提高工作效率和提升數據的準確性。

在多數組織的智能自動化流程業務中,OCR是應用最多的人工智能技術之一。OCR與RPA的結合可以將組織中超過70%的無紙化業務實現自動化,其效率將是人工的5倍以上。下面本文將詳細介紹OCR與RPA在智能自動化中的一些案例和注意事項。
什么是OCR?它是如何工作的?
OCR是指電子設備(例如掃描儀或數碼相機)檢查紙上打印的字符,通過檢測暗、亮的模式確定其形狀,然后用字符識別方法將形狀翻譯成計算機數據的過程。
針對印刷體字符,采用光學的方式將紙質文檔中的文字轉換成為黑白點陣的圖像文件,并通過識別軟件將圖像中的文字轉換成文本格式,供文字處理軟件進一步編輯加工的技術。衡量一個OCR系統性能好壞的主要指標有:拒識率、誤識率、識別速度、產品的穩定性、易用性等。
ICR與OCR的區別
OCR和ICR的核心區別在于: OCR其功能僅限于識別看起來相同的字符,而ICR是將傳統字符識別與機器學習進行深度融合,可以從非標準文檔中解析數據,有助于將手寫文本字符轉換為機器可讀的格式。
OMR(光學標記識別):
該技術有助于識別帶有刻度線、復選標記以及下劃線的字符。OMR的特點是閱讀準確(即對涂點的識別有極高的精確度,誤碼率小于千萬分之一)、 閱讀速度快,每秒鐘可以處理一千多個信息點。
OBR (Optical barcode reader):
OBR主要用于讀取文檔中的條形碼數據。
上述的這些識別技術主要用于日常工作的數據識別和提取。下面將介紹一些實際的案例。
半結構化文件:
半結構化文檔沒有正式的數據結構。該文檔通常是相同的,但是設計和布局可能會有所不同。信息將被標記在文檔中,但是信息的位置可能因文檔而異。常見的半結構化文檔識別案例有發票提取和整理,采購訂單的識別等。在OCR識別半結構化文件后,將其轉化成結構化數據,然后再交由RPA做進一步的自動化處理。
非結構化數據:
非結構化數據是數據結構不規則或不完整,沒有預定義的數據模型,不方便用數據庫二維邏輯表來表現的數據。包括所有格式的辦公文檔、文本、圖片、XML,HTML、各類報表、圖像和音頻/視頻信息等等。
非結構化數據在任何地方都可以得到。這些數據可以在你公司內部的郵件信息、聊天記錄以及搜集到的調查結果中得到,也可以是你對個人網站上的評論、對客戶關系管理系統中的評論或者是從你使用的個人應用程序中得到的文本字段。或者是在公司外部的社會媒體、你監控的論壇以及來自于一些你很感興趣的話題的評論。

企業哪些業務需要OCR?
多數情況下,OCR主要用于簡化紙質業務并將其轉化成數字化業務,例如:PDF、掃描文件、紙質發票、傳真和手寫文檔等。
適用的行業包括:
-
金融行業:員工入職、客戶開戶、貸款申請、數據校審等。
-
制造行業: 訂單處理、匯款、倉庫盤點等。 -
人力資源: 員工入職、篩選簡歷、人力資源記錄處理等。 -
供應鏈管理: 訂單和貨運跟蹤、提貨單、貨物訂單等。
當OCR用于圖像識別提取數據時,需要注意哪些事情?
-
需要高清圖片:大多數市場上的OCR引擎對圖像質量都有著最低要求。通常圖像每寸的DPI要求在200—300之間,如果可以提供500以上DIP圖像,這將極大地提高OCR的識別效率和準確率。
-
盡量不要手寫文本:一些業務流程如制造商審批、數據審計、檢查員簽字時可能需要手寫簽字。但是手寫文本的形體等原因,會降低文檔的質量影響OCR的識別效率。
-
不要掃描副本文件:有的時候在打印和掃描圖片時,會掃描副本文件,這將影響圖片的質量從而影響OCR的提取效率。
-
使用純白背景:通常業務文檔包含很多設計元素,如紋理、背景圖像等。這將嚴重阻礙OCR的識別。
-
保持規定格式:一般情況下OCR的識別格式比較廣泛,包括:TXT、EML、XLSX、VSD、HTML、DOCX、XLS、VSDX、DOC、PPTX、HTM、PPT、RTF、BMP、PCX、DCX、JPEG、TIFF、GIF、PNG、PDF等格式。盡量不要提供這些格式以外的文件,否則將造成無法識別。
下面這個實例將幫助大家更好的理解RPA與OCR的工作原理:
1、用戶收到一封帶有圖片的電子郵件。
目前全球的RPA廠商正在通過與不同的人工智能技術相結合,來提升競爭力贏得市場。而OCR在頻率、業務范圍、以及對業務影響上都領先于其他技術。通過OCR來處理那些非結構化業務,也使得RPA的自動化范圍可以擴展到更多的領域中。
未經允許不得轉載:RPA中國 | RPA全球生態 | 數字化勞動力 | RPA新聞 | 推動中國RPA生態發展 | 流 > 詳解RPA與OCR的工作機制與原理
heng.png)
 RPA CoE x GPT = 未來企業
RPA CoE x GPT = 未來企業 RPA技術的進階之路:智能化、多元化與增強發展
RPA技術的進階之路:智能化、多元化與增強發展 沒錢沒需求,企業數字化轉型怎么干?
沒錢沒需求,企業數字化轉型怎么干? 從ChatGPT數據泄露事件,看組織安全穩定自動化的重要性
從ChatGPT數據泄露事件,看組織安全穩定自動化的重要性














熱門信息
閱讀 (14728)
1 2023第三屆中國RPA+AI開發者大賽圓滿收官&獲獎名單公示閱讀 (13753)
2 《Market Insight:中國RPA市場發展洞察(2022)》報告正式發布 | RPA中國閱讀 (13055)
3 「RPA中國杯 · 第五屆RPA極客挑戰賽」成功舉辦及獲獎名單公示閱讀 (12964)
4 與科技共贏,與產業共進,第四屆ISIG中國產業智能大會成功召開閱讀 (11567)
5 《2022年中國流程挖掘行業研究報告》正式發布 | RPA中國